
We define web semantics as significant attributes, descriptions, representations, and relationships, of digital objects people find on the web. Web semantics provide valuable contextual information, allowing people to make sense of and act on found objects. A common example is product semantics, including price, brand, seller, specs, pictures, reviews, and related products, describing items for sale on many e-commerce websites. These semantics are essential for shoppers to assess if a product meets their needs, compare choices, and make purchasing decisions. Likewise, on social media websites, @usernames, #hashtags, and other linked associations allow people to compare and synthesize diverse perspectives, helping them develop mutual understanding of a topic.
We define exploratory browsing as a creative process through which users seek and traverse diverse and novel information as they use the web to investigate a topic or conceptual space. Web semantics facilitate developing exploratory browsing interfaces that visually present links to related information. The goal is to promote serendipitous discovery, which is critical in diverse human activities. For instance, in scholarly research, exploratory browsing using semantics, e.g, authors, year / venue, references, and citations for an article supports contextualizing with originating and subsequent connected research; it helps researchers in gaining diverse and novel ideas existing within the conceptual space.
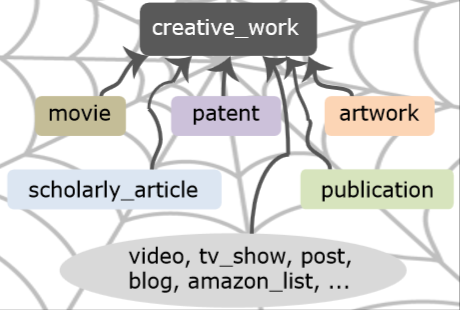
BigSemantics is an open source architecture, language, and library, for representing, extracting, and consistently presenting explorable web semantics of diverse types. Developers author types (wrappers), using the meta-metadata language, to define reusable semantic data models, rules for extracting semantics from regular webpages, and presentation semantics that guide how information will be presented to users. BigSemantics comes with a non-trivial repository of wrappers, addressing popular websites and common use cases involving searches, products, digital libraries, creative work, and social media.
Building upon BigSemantics, we are developing dynamic exploratory browsing interfaces that enrich web experience through explorable web semantics. An example web application, the Metadata In-Context Explorer (MICE), allows users to serendipitously encounter new information in the same context, while maintaining the sense of goals and whereabouts in the navigation process.
projects
 IdeaMâché
is our previous web app that uses
free-form web curation as a medium of expression.
Curation is the process of creating and assembling information in meaningful exhibits, for people to think about.
IdeaMâché
is our previous web app that uses
free-form web curation as a medium of expression.
Curation is the process of creating and assembling information in meaningful exhibits, for people to think about.
 TweetBubble
is a
Chrome extension
that helps Twitter users
engage in exploratory browsing, by following associational chains of
tweets through #hashtags and @users.
Our study show this increases the variety
of content people explore,which helps you develop multiple perspectives on a topic.
TweetBubble makes browsing a more fun and fluid experience.
TweetBubble
is a
Chrome extension
that helps Twitter users
engage in exploratory browsing, by following associational chains of
tweets through #hashtags and @users.
Our study show this increases the variety
of content people explore,which helps you develop multiple perspectives on a topic.
TweetBubble makes browsing a more fun and fluid experience.
publications
 Jain, A., Kasiviswanathan, G., Huang, R.,
Towards Accurate Event Detection in Social Media: A Weakly Supervised Approach for Learning Implicit Event Indicators,
Computational Linguistics (COLING) 2016 Workshop on Noisy User-generated Text (W-NUT), Osaka, Japan.
Jain, A., Kasiviswanathan, G., Huang, R.,
Towards Accurate Event Detection in Social Media: A Weakly Supervised Approach for Learning Implicit Event Indicators,
Computational Linguistics (COLING) 2016 Workshop on Noisy User-generated Text (W-NUT), Osaka, Japan.
 Qu, Y.
Supporting Ideation by Integrating Exploratory Search, Browsing, and Curation,
Proc. ACM Conference on Human Information Interaction and Retrieval (CHIIR) 2016, 361-363.
http://dx.doi.org/10.1145/2854946.2854948
Qu, Y.
Supporting Ideation by Integrating Exploratory Search, Browsing, and Curation,
Proc. ACM Conference on Human Information Interaction and Retrieval (CHIIR) 2016, 361-363.
http://dx.doi.org/10.1145/2854946.2854948
 Jain, A., Lupfer, N., Qu, Y., Linder, R., Kerne, A., Smith, S. M.,
Evaluating TweetBubble with Ideation Metrics of Exploratory Browsing,
Proc. ACM Creativity and Cognition 2015, 178-187 [28%].
Jain, A., Lupfer, N., Qu, Y., Linder, R., Kerne, A., Smith, S. M.,
Evaluating TweetBubble with Ideation Metrics of Exploratory Browsing,
Proc. ACM Creativity and Cognition 2015, 178-187 [28%].
 Wilkins, J., J�rvi, J., Jain, A., Kejriwal, G., Kerne, A., Kumar, V.,
EvolutionWorks: Towards Improved Visualization of Citation Networks,
Proc. IFIP International Conference on Computer-Human Interaction (INTERACT) 2015. [29.9%].
Wilkins, J., J�rvi, J., Jain, A., Kejriwal, G., Kerne, A., Kumar, V.,
EvolutionWorks: Towards Improved Visualization of Citation Networks,
Proc. IFIP International Conference on Computer-Human Interaction (INTERACT) 2015. [29.9%].
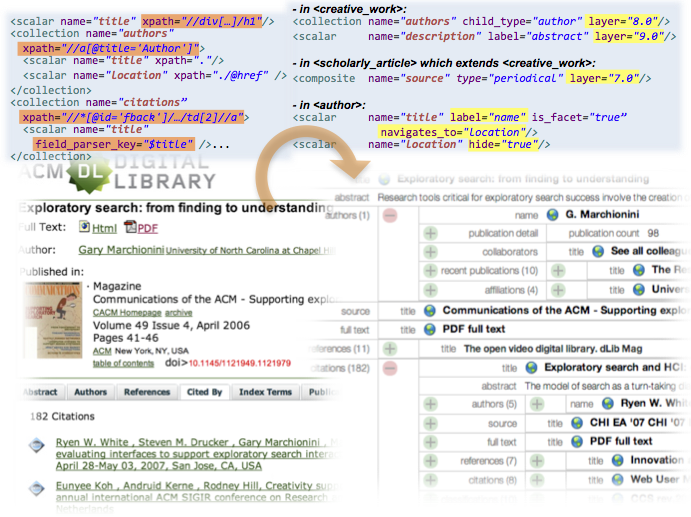 Qu, Y., Kerne, A., Lupfer, N., Linder, R., Jain, A.,
Metadata Type System: Integrate Presentation, Data Models and Extraction to Enable Exploratory Browsing Interfaces,
Proc. ACM Engineering Interactive Computing Systems (EICS) 2014, 107-116 [18%].
http://dx.doi.org/10.1145/2607023.2607030
[video]
Qu, Y., Kerne, A., Lupfer, N., Linder, R., Jain, A.,
Metadata Type System: Integrate Presentation, Data Models and Extraction to Enable Exploratory Browsing Interfaces,
Proc. ACM Engineering Interactive Computing Systems (EICS) 2014, 107-116 [18%].
http://dx.doi.org/10.1145/2607023.2607030
[video]
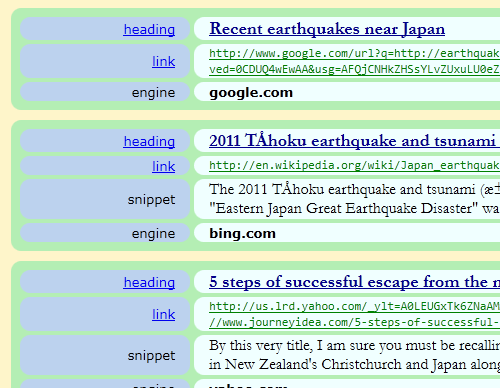 Qu, Y., Kerne, A., Webb, A.M., Herstein, A.
Interoperable Metadata Semantics with Meta-Metadata: A Use Case Integrating Search Engines,
Proc ACM DocEng 2011, 171-174 [53%].
http://dx.doi.org/10.1145/2034691.2034729
Qu, Y., Kerne, A., Webb, A.M., Herstein, A.
Interoperable Metadata Semantics with Meta-Metadata: A Use Case Integrating Search Engines,
Proc ACM DocEng 2011, 171-174 [53%].
http://dx.doi.org/10.1145/2034691.2034729
 Kerne, A., Qu, Y., Webb, A.M., Damaraju, S., Lupfer, N., Mathur, A.
Meta-Metadata: A Metadata Semantics Language for Collection Representation Applications,
Proc ACM Conference on Information and Knowledge Management, 1129-1138. [12.7%]
http://dx.doi.org/10.1145/1871437.1871580
Kerne, A., Qu, Y., Webb, A.M., Damaraju, S., Lupfer, N., Mathur, A.
Meta-Metadata: A Metadata Semantics Language for Collection Representation Applications,
Proc ACM Conference on Information and Knowledge Management, 1129-1138. [12.7%]
http://dx.doi.org/10.1145/1871437.1871580
 Kerne, A., Damaraju, S., Kumar, B., and Webb, A.
Meta-Metadata: A Semantic Architecture for Multimedia Metadata Definition, Extraction, and Presentation,
Poster and Demo Proceedings of the 3rd International Conference on Semantic
and Digital Media Technologies.
Kerne, A., Damaraju, S., Kumar, B., and Webb, A.
Meta-Metadata: A Semantic Architecture for Multimedia Metadata Definition, Extraction, and Presentation,
Poster and Demo Proceedings of the 3rd International Conference on Semantic
and Digital Media Technologies.
 Koh, E., Kerne, A., Berry, S.,
Test Collection Management and Labeling System,
Proc ACM DocEng 2009, 39-42 [29.6%].
http://dx.doi.org/10.1145/1600193.1600203
Koh, E., Kerne, A., Berry, S.,
Test Collection Management and Labeling System,
Proc ACM DocEng 2009, 39-42 [29.6%].
http://dx.doi.org/10.1145/1600193.1600203